
AI Agent Teams for Business: What We’ve Learned Building Ours (OpenClaw)
This article is adapted from our video walkthrough of the system. If you prefer to watch, here’s the full video.
Our Production Agent Team
Our AI agent team publishes researched, reviewed, brand-aligned content for $2-5 per piece, autonomously. Here’s how we built it and what went wrong along the way.
Most businesses thinking about AI are still stuck on the chatbot model: one window, one conversation, one prompt at a time. That works for answering questions. It doesn’t work for running business operations.
We spent the last several months building something different: a production multi-agent system where specialized AI agents handle research, content strategy, writing, analytics, and publishing across our entire content operation. Not as a proof of concept. As the actual system running our business every day.
The technology we built on is called OpenClaw, which sits firmly in the agentic tier of AI maturity. It’s powerful, and the decisions involved aren’t obvious from the outside.

How Agents Access What They Know
An agent without knowledge is just a language model guessing. The first thing we had to solve was how to give our agents access to everything they need to do their jobs.
We had an advantage here: two years of documented meetings, strategies, video transcripts, customer data, and operational knowledge already stored in structured files. That baseline meant we could skip the knowledge-building phase and focus on the architecture of how agents access that information.

There are roughly six approaches to agent memory right now. The default with most frameworks is nothing, which is obviously bad. You can use structured folders, built-in memory search, external services like Mem0, or even a SQL database with semantic search. We tested several and landed on Obsidian paired with QMD, a local semantic search tool.
The reasoning was practical. Our knowledge isn’t heavily tabled data that needs SQL. It’s a collection of strategy documents, brand rules, customer research, and operational procedures. Markdown files are portable, easy to update, and indexable. QMD runs a semantic search index that rebuilds overnight, so agents can query the knowledge base naturally. Everything stays on our infrastructure. No third-party service reading every query.
That portability matters more than it sounds. The same knowledge base feeds our agents, syncs to team members who need it, and serves as the foundation for the entire operation. OpenClaw is just another application layer on top of knowledge we were already maintaining.
Choosing Models for Agent Work
We’ve tested models from Anthropic, Google, and Z.ai extensively. The results diverged significantly from benchmark predictions.
Google’s models couldn’t consistently understand their own environment. We’d have arguments where the model would insist it didn’t have memory access when it clearly did, or claim it couldn’t create a scheduled task when that capability was configured and working. This happened with Gemini 3.1 and the smaller Flash models, so sadly we had to abandon Google entirely for agent work. (At least for now until they improve!)
Anthropic’s models, particularly the Claude family, understood the OpenClaw ecosystem immediately. They grasped where they were running, what tools they had access to, and how to improve their own workflows. Point them at the OpenClaw documentation and they build from it. The consistency of instruction-following is what separates Anthropic from everything else we tested.
Z.ai models are dramatically cheaper, we tested and use GLM-4.7 and GLM-5.0. They may match other models on benchmark tests, but benchmarks don’t measure what matters for agents: do they follow instructions to the letter, consistently, across hundreds of automated runs? Do they escalate when they should? On those criteria, nothing we’ve tested comes close to Anthropic’s models.
The practical outcome: we use different models for different jobs. High-reasoning tasks like writing and editorial review run on Anthropic’s Opus. Low-stakes tasks like status reporting or simple file operations run on cheaper models. Each scheduled job specifies its own model, so we optimize cost without sacrificing quality where it matters.
That per-job model assignment is one of the most impactful decisions we made. Our content writer uses an Opus-class model for drafting, but communicates status updates through a much cheaper model. Cost drops significantly, quality stays where it needs to be.

The Architecture: Specialists Connected by Structured Handoffs
Single agents fail at complex work because they’re trying to hold too much context at once. You wouldn’t hire one person to be your researcher, strategist, writer, editor, and publisher. The AI version of that idea fails the same way.
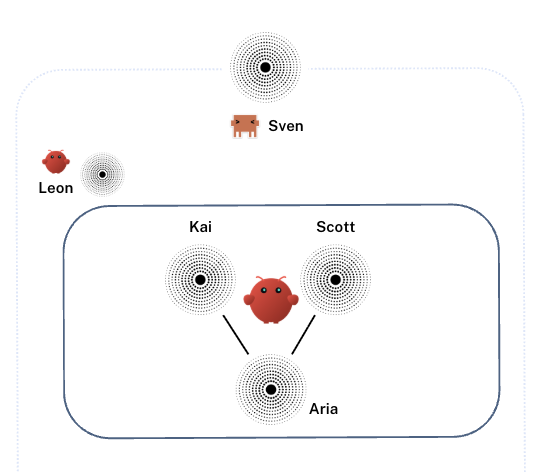
Our system uses specialist agents, each with a narrow focus:
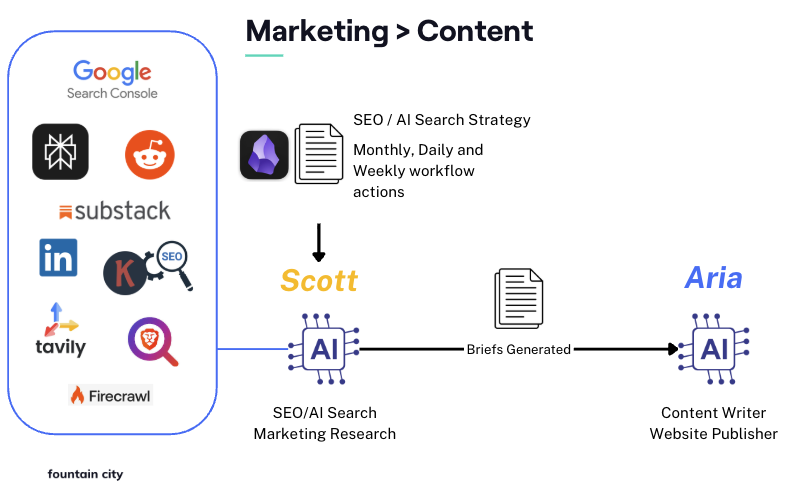
- Scott: A research and SEO agent that monitors search trends, competitive positioning, Reddit discussions, LinkedIn topics, and keyword data. It produces structured briefs for what content to create and why.
- Kai: A content strategy and CRO agent that owns the coherence of the entire site. It tracks which topics are covered across all pages, flags overlap or gaps, and ensures the site tells a consistent story rather than a collection of disconnected posts. On the analytics side, Kai monitors GA4 data and conversion metrics, identifies underperforming pages, and generates work orders for Aria when pages need updating. Where Scott looks outward at what to create next, Kai looks inward at what already exists and whether it’s working.
- Aria: A writing and publishing agent that takes briefs and work orders, writes drafts against our brand voice guidelines, self-reviews, generates images, and publishes to WordPress.
- Leon: A monitoring agent that tracks API costs, audits whether other agents are following their processes, and flags issues before they compound.
The agents don’t communicate through some sophisticated real-time messaging protocol. They use file drops. Each agent has an inbox folder. When one agent finishes work, it leaves a structured file where the next agent will find it. It’s a digital assembly line built on text files and scheduled jobs, and it works because the interfaces between agents are precisely defined.
Work moves through stages using scheduled jobs at set intervals: research runs, then writing, then review, then publishing. Each job processes one item and exits. If something is blocked, the system moves to the next item and flags the blocker for a human.

What We’ve Learned About Managing Agents
Agents need management. Not in the micromanagement sense, but in the same way any team needs clear expectations, defined processes, and someone watching the overall system.
Split tasks that have quality problems. This was one of the biggest improvements we made. When an agent writes and self-reviews in the same pass, quality is inconsistent. When you split writing and review into separate stages, each with its own dedicated run, quality jumps. The writing pass gets ideas down. The review pass applies the style guide and catches problems. You can extend this further: separate research from writing, separate drafting from editing. Anywhere you see inconsistency, splitting the task usually fixes it.
Let agents think out loud. We build explicit steps into each workflow where the agent documents its reasoning in a separate analysis file before producing the final deliverable. This isn’t busywork. The act of articulating reasoning improves the output, just like it does for humans. It also creates an audit trail.
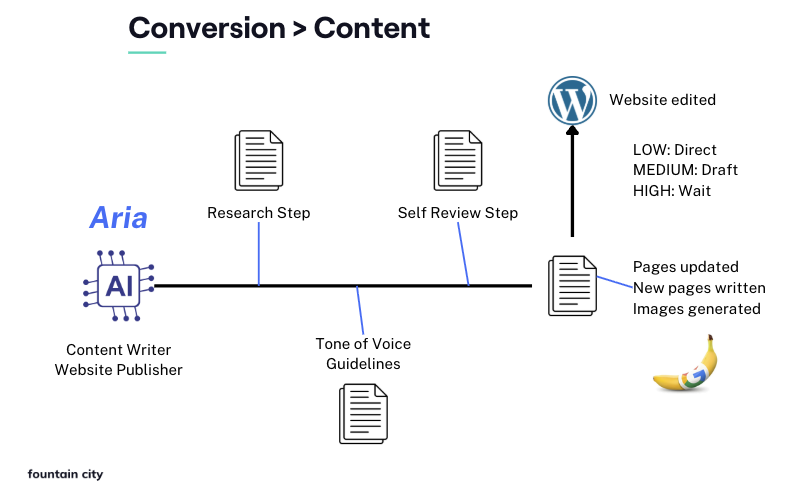
Risk-tier everything. We classify every task as low, medium, or high risk. Low-risk changes like updating a meta description go through automatically, no human approval needed. Medium-risk work like new pages or changes to core site pages gets submitted as a draft or clone for review. High-risk tasks that involve external integrations or major structural changes wait for explicit approval. This lets the system run autonomously on the 80% of work that doesn’t need human judgment, while keeping humans in the loop for decisions that matter.
Monitor costs actively. API calls add up fast, especially early in a build when you’re iterating on prompts and processes. We run a dedicated monitoring agent that tracks per-task costs, flags excessive API usage, and produces regular reports. We’ve gotten content production down to roughly $2 to $5 per published piece including all research, writing, review, and image generation. That number was much higher in the first weeks while we were optimizing model assignments and workflow efficiency.

Security for Autonomous Agents
Autonomous agents with access to your systems create attack surfaces worth taking seriously. We started addressing this early.
Scope agent permissions tightly. Every agent only has access to the tools and directories it needs for its specific job. Our writing agent can publish to WordPress but can’t modify the contact form or change where form submissions are sent. That’s a real scenario: if an agent can change a form endpoint, a prompt injection attack could redirect customer inquiries to a competitor. You have to think about what damage a compromised agent could do, then prevent it structurally.
Lock down the infrastructure. Our server only accepts connections from a specific IP. The server can only connect to our web server. There’s no email integration, which eliminates the entire class of prompt injection attacks that come through inbound messages.
Be careful with dependencies. OpenClaw and similar frameworks have a lot of moving parts: plugins, skills, integrations. Each one is a potential vulnerability. As the system becomes more critical, you need to treat updates the same way you’d treat updates to production software. Audit what you install. Consider waiting before applying updates unless they’re security patches.
Understand your model provider risk. Every API call sends data to an external provider. Whether that’s a US company, a Chinese company, or anyone else, someone is processing your prompts. If that’s unacceptable for your use case, you can run local models, but you’ll trade capability for control. For the work we’re doing, the Opus-level reasoning from Anthropic is an unavoidable external dependency. We accept that trade-off with eyes open.
The Tools That Actually Matter
We’ve integrated a lot of tools. These are the ones that earn their keep:
- Perplexity API for research and competitive analysis. Essential for seeing how brands appear in AI-powered search results. We wouldn’t build an agent research stack without it.
- Keywords Everywhere for SEO keyword data at $7/month instead of the $500+ that Semrush or Ahrefs charge for API access. This is the kind of pricing gap that agents create: when your researcher is an API consumer, the enterprise pricing model of traditional SEO tools makes no sense.
- Google Search Console and Google Analytics for understanding how our content performs and how visitors behave on the site.
- Tavily for web research and content extraction (we switched from Brave, keeping Brave only for SERP position checks).
- Playwright for visual verification. When an agent builds or edits a page layout, it needs to see what it produced. Without screenshots of desktop and mobile views, you’re trusting the agent to get visual design right blind. That doesn’t work.
We evaluated and rejected several tools too. ClickUp turned out to be unnecessary overhead. AgentMail created too large an attack surface. ActiveCampaign integration is on the list for later, once the core system is fully stable.
Building Your First Agent Team
If you’re starting from scratch, the lessons compress into a few principles.
Start with two agents and one clean handoff. Find a process where work moves from collection to execution: data gathering feeds analysis, research feeds writing, monitoring feeds reporting. Define exactly what Agent A sends to Agent B. Format, fields, structure. Fuzzy interfaces produce fuzzy results.
Use scheduled jobs instead of real-time orchestration. For most business workflows, you don’t need agents talking to each other in real time. A research agent runs at 7 AM, a writing agent picks up the output at 8 AM. Simple, debuggable, and you can assign different models to each job for cost optimization.
Invest in knowledge management before you invest in agents. If your business processes, rules, and institutional knowledge aren’t documented somewhere an agent can access them, the agent will guess. It will guess confidently, and it will guess wrong. The documentation work you do before building agents pays for itself many times over.
Plan for the system to need iteration. Our first month of agent operation involved constant refinement: adjusting prompts, splitting tasks, reassigning models, tightening permissions. That’s normal. Budget time and resources for optimization, not just initial setup.

Where This Goes Next
Our current system handles content research, strategy, writing, review, and publishing autonomously. The agentic architecture is proven and stable.
The next layer is expanding into adjacent workflows: social media distribution, ad management connected to Google Ads with automatic landing page optimization, and deeper autonomous monitoring that can catch and fix issues before they’re flagged. We’re also working on productizing what we’ve built so other businesses and agencies can deploy similar systems through our AI agentic automation services.
Gartner forecasts that 40% of enterprise apps will embed task-specific agents by the end of 2026, up from fewer than 5% in 2025. They’ve tracked a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025. The interest is there. Most businesses know they need agent teams. The challenge is deploying them without burning months on the same mistakes everyone else is making.
We’ve made most of those mistakes already. The system running our business today is the result of working through them.
Frequently Asked Questions
Do these agents talk to each other automatically?
Yes, that’s the core of a multi-agent system. In our setup, agents pass structured data to each other through file drops and scheduled handoffs. An orchestration layer manages the sequence. Some systems use real-time messaging between agents, but for most business workflows, scheduled handoffs are simpler to debug and more reliable.
How much does it cost to run an agent team?
More than a $20 ChatGPT subscription, less than a single employee. Our production system runs content research, writing, review, image generation, and publishing for roughly $2 to $5 per finished piece. Total monthly costs depend on volume and which models you assign to which tasks. Expect hundreds per month for serious production workloads, and plan for higher costs during the first few weeks while you optimize model assignments and workflow efficiency.
Does this replace my operations team?
No. It changes what they do. Someone still needs to design the workflows, handle edge cases the agents can’t resolve, and make judgment calls on strategy. Think of it as promoting your ops team to agent managers. The repetitive execution gets automated. The thinking and decision-making stays human.
What software do I need to build this?
For code-heavy builds, frameworks like Codex, CrewAI, AutoGen, or LangChain provide the scaffolding. We built on OpenClaw with Claude Code, which handles the infrastructure layer: scheduling, tool access, memory, and inter-agent communication. The choice depends on how much you want to build versus configure. If you want a managed approach, our managed Autonomous AI Agents service handles all the setup, security, quality and continuous improvement.
How is this different from Zapier or Make automations?
Zapier and Make are linear: if X happens, do Y. They’re rigid and break when inputs vary. Agents are reasoning-based. They can handle ambiguous inputs, make decisions based on context, and adapt when something unexpected comes up. An automation triggers a fixed sequence. An agent evaluates a situation and chooses a response. For structured, predictable workflows, automations work fine. For anything that requires judgment or flexibility, agents are the better fit.
