
How to tap into effective high-speed and high-quality AI-assisted coding
Over the holidays our team hit a new breakthrough with AI-assisted coding where we were able to substantially accelerate our code quality and quantity once we put these practices into place.
Last month we grinded through so many AI-assisted coding challenges that we ended up at a new more sophisticated approach that has resulted in significant speed gains. Today I will be diving deep into what those approaches are so that you may benefit from them and apply them to your organization.
Want to watch this blog post in video format instead?
The Problem With Single-Agent AI Workflows
When our developers first start using AI assistants, the experience for us felt magical. The AI writes code at incredible speed. It has vast knowledge. It can analyze log files in seconds that would take hours manually, but then the bubble is burst.
Context drift happens fast. The AI starts forgetting critical details or fixating on the wrong elements.
What started as extremely fast code output slowly dwindles its gains as we get stuck in countless issues.
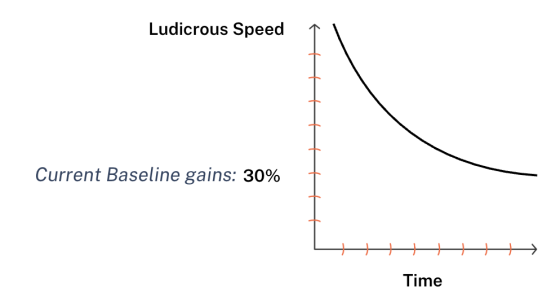
AI assisted coding ends up still being beneficial but it is hard to get above about 30% productivity gains.
For example the AI can confidently claims it fixes bugs when it hasn’t tested anything. It can cheat, taking shortcuts you didn’t authorize. It writes code so fast that reviewing it becomes nearly impossible. And because there’s no real learning between prompts and sessions, you’re rebuilding context from scratch every single time…
We have also noticed fix loops: where the AI fixes one thing but breaks another, then fixes that but breaks the first thing again. AI can also start to reference existing incorrect code as gospel truth, and then propagate those errors throughout new implementations.
The 30% gains come easy. Getting beyond that required us to rethink the entire structure.
Architecture Changes Everything
The breakthrough came when we stopped trying to make one AI agent better at everything and instead built a control architecture with separate agents handling different thinking levels.
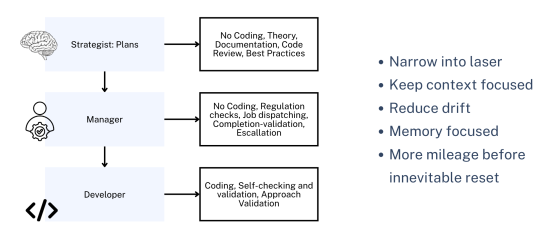
Three distinct layers:
Strategy Layer: Senior-level thinking about planning, documentation, design patterns, and best practices. No code gets written here. This agent works with a powerful model (Opus, high-end ChatGPT, or Gemini Pro with thinking enabled) because it needs to understand large context windows and complex systems theory.
Management Layer: Creates job descriptions for what needs to be coded, delegates work, and validates results. This agent bridges strategy and execution.
Development Layer: Writes code, self-validates work, and can push back on instructions when they don’t make sense. This agent uses a less expensive model (Gemini Flash or equivalent) because its context window stays focused on implementation details.
Keeping these contexts separate prevents littering strategy discussions with implementation details and vice versa. Each conversation stays clean and focused.
The Obsessive Validation Approach
Conventional development wisdom says excessive validation slows you down. With AI-assisted coding, that wisdom inverts.
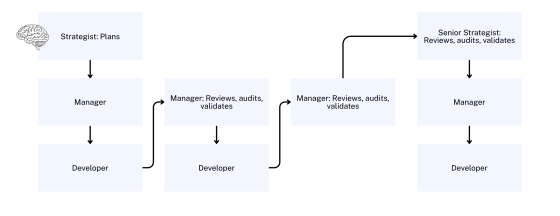
Because AI operates at such high speed, you can afford obsessive process. We built validation into every step:
- The developer AI writes code and logs everything it did to prove completion
- The developer analyzes its own logs to self-check
- The manager reviews logs and provides feedback
- Documentation gets updated immediately upon validation to prevent drift between specs and reality
- The strategist does final review and audit before moving to the next phase
This sounds like overkill. With AI speed, these multiple validation layers take minutes, not hours. We’re talking “measure three or four times, cut once” philosophy, and the measuring happens so fast it’s negligible compared to the confidence it provides.
Each step proves itself complete AND proves it has everything needed for the next step to succeed. Nothing moves forward until validation passes at all levels. Test driven development is your savior: Define and test all your edge cases upfront and use the AI to generate them. Set up Unit Tests and have the AI run them.
Work From Big to Small
Traditional development often works iteratively and builds up, perhaps one function at a time in isolate, built and tested. With multi-agent AI systems, the opposite works better. Build top-down with large paint strokes then fill in the details as your get to the detailed work. Have the AI build out an entire class in a single prompt, referencing the documentation to do so. This works so much better than getting the AI to write one function, or part of a function.
We document all interactions between system components first: like a UML diagram showing class relationships and data flow. The strategist creates this documentation working with the developer to ensure feasibility.
Then the developer builds one component at a time, logging everything needed to prove completion. The manager reviews code and logs and provides feedback. Documentation gets updated if anything changed during implementation. Then we move to the next component.
For our hydraulic simulation project, we created about 5,000 lines of code across 15 class files in nine phase steps. Total implementation time: about 12 hours. We found only three bugs, fixed them in 30 minutes, and everything validated through extensive logging.
Planning took a full day upfront: documentation, frameworks, research to ensure proper infrastructure. So roughly 18 hours of pure creation time. A senior developer might traditionally have needed three to four weeks for the same work.
The Cost of Rolling Back Drops Dramatically
For human developers, backing out of a dead end carries significant cost. You’ve invested hours or days going down a particular path. Admitting it’s wrong and starting over feels expensive, so we push through even when we shouldn’t.
With AI writing code at 10x speed, the calculation changes completely. Rolling back to a previous commit, developing a better methodology, and going forward again costs nothing, the AI will write you a new essay of code in an instant… so the “fuel” is cheap, the correct coordinates for the correct destination is the real “cost”. Focus on the destination, roll back. Re-group, figure out what was missing in your documentation, re-develop the approach, define better your test criteria… then with your better coordinates in place, and the code rolled back, “launch” towards your new objective. The code being written is “cheap” it is “fast”, it comes out instantly. The effort has shifted from writing code to guiding the process.
This changes risk management. We commit frequently. We back out aggressively when we notice fix loops or incorrect patterns taking hold. We bring second and third opinions from humans working with different AI agent layers when implementation steps fail.
It turns out the developer who led our hydraulic simulation project never wrote a single line of code directly. But they needed senior-level thinking throughout: for process design, documentation, methodology, supervision, code review, strict and obsessive validation, and prompt engineering to pass the right context between agent layers.
What This Reveals About AI System Design
The multi-agent approach solves several problems simultaneously:
Memory limitations become less critical when each agent maintains focused context rather than trying to remember everything across all thinking levels.
Cost optimization happens naturally: expensive models handle strategy while cheaper models execute, reducing AI-usage costs per-project significantly.
Error propagation gets caught at multiple layers before becoming ingrained in the codebase.
Specialization allows each agent to develop deeper expertise in its domain rather than being mediocre at everything.
The pattern applies beyond coding. Any complex knowledge work that AI assists with can benefit from similar architecture:
- Separate research from synthesis from execution
- Keep context windows tightly focused on specific tasks
- Build highly detailed quality assurance validation between layers rather than only at the end
- Use cheaper models for routine work and expensive models for strategic thinking
Where This Leads
Right now, we’re manually moving information between agent layers. A human takes the strategist’s analysis, pulls out relevant sections, and feeds them to the developer with additional context.
That won’t stay manual forever. We are sure we, and perhaps you, will start building networks where these different agents communicate directly, looping through their processes with human oversight rather than human intervention in every step.
Our 12-hour implementation phase ran smoothly enough that it could theoretically have happened entirely automated while we worked on something else. We’re not quite there yet, but the path is visible.
AI models will also keep improving. Better memory management, real learning rather than just context building, reduced hallucination, stronger reasoning; all the current limitations will gradually resolve. So I am sure this particular methodology will become less necessary as the underlying technology improves.
But right now, in January 2026, the multi-agent control architecture approach breaks through the 30% productivity ceiling that most teams are stuck behind.
What We Learned
A few patterns have emerged that transfer to other AI implementation projects:
Upfront documentation pays compounding returns. The day spent planning our hydraulic simulation saved weeks during implementation (deadends, refactoring, starting over, human coding intervention). When AI has clear specifications and design patterns, it operates far more reliably.
Explicit permission structures matter. We have to tell the developer AI that it has authority to question instructions and push back. Without explicit permission, AI agents default to compliance even when they “know” something’s wrong. Make a note about things the AI assumes wrongly and start to explicitly point out those assumptions from then on out.
Rollback thresholds should be aggressive. Watch for fix loops, feature creep within bug fixes, and unwanted deletions. Back out immediately rather than pushing through.
Context corruption happens faster than expected. Too much documentation is as harmful as too little. Keep it focused on what’s actually important for each agent’s specific role.
Testing These Ideas
We’re continuing to refine this approach across different types of projects. Scientific simulations (like hydraulics) proved to be an excellent test case because they require theoretical understanding translated into precise implementation.
Our next tests will involve different problem domains to see where the methodology holds up and where it needs adaptation. We’re particularly interested in projects that combine multiple knowledge areas or require creative problem-solving alongside technical execution.
If you’re running development teams and want to discuss how this might apply to your specific context, I’m easy to reach. 🙂 These ideas are still evolving, and learning what works in different environments helps refine the methodology. I would love to hear what is working for you, if you have improvements to this we can incorporate or if you have any questions.
