Autonomous AI Content Pipeline: Real Benchmarks From 30 Days of Production
The Real Thesis: Quality, Not Cost
Building an autonomous content pipeline is not hard. Getting five AI agents to produce something that looks like an article takes a weekend. Getting five AI agents to produce something you would actually publish under your own name, consistently, with minimal human intervention? That took months of iteration and a deliberate investment in quality systems that made the per-article cost go up, not down.
The first draft of this article led with cost savings. That was wrong. The writing agent assumed readers compare price first. They don’t. The first question is whether the output is good enough to publish, and how much of their time it takes.
Everything below comes from our own production logs, API invoices, and content management records. Where we compare to industry benchmarks, we cite the source. Where a number is estimated, we say so. The system architecture is documented in a separate post covering how the pipeline works. This post is the companion piece: the numbers, the failures, and what we learned.
The Quality Architecture
The production system that wrote, reviewed, and prepared this article for publishing runs on a single AWS instance. For context on how AI agent teams work in business operations, that piece covers the organizational model. A separate SEO research agent generates the initial content briefs from search console data and competitive analysis. The pipeline architecture is documented in a companion piece; this article is about what sits on top of it.
The quality systems layered on top of the pipeline stages are what drive both the per-article cost and the output quality. These systems are the reason per-article API costs rose from $2 to $5 in the early weeks to $8.50 in the most recent four-week period. Each one was added because we found a specific quality gap and decided the cost increase was worth closing it.
Gates Before Writing Begins
Content enters one of four insight tiers: practitioner-level insight (the goal), original research or data, original framing of existing information, or commodity content that restates widely available knowledge. This insight tiering screens for EEAT potential at the idea stage. Can this topic demonstrate genuine expertise and experience? Does Fountain City have first-party data or practitioner experience? Commodity content in the lowest tier gets held at the idea stage because it cannot demonstrate strong EEAT regardless of how well it is written. This is the early quality gate.
Controls During and After Production
When you publish 20+ articles per month, the risk of five articles all citing the same statistic or using the same framework is real. A dedicated deduplication stage catches overlapping ideas, shared proof points, and recycled examples between recent articles before they reach a reader.
Anything one article establishes enters a shared knowledge base immediately, seeding future articles. The system accumulates institutional knowledge with each piece it produces. Article 30 has access to context that article 1 did not.
A separate AI agent with a protected context window runs an editorial pass after the writing agent’s self-review. This agent catches framing issues, quality gaps, and consistency problems the writing agent cannot see in its own output. The context isolation matters: a writing agent reviewing its own work has the same blind spots that produced the issues in the first place. The editorial agent starts fresh. Before it sees the draft, the writing agent reviews its own work against documented brand voice standards, sourcing requirements, and formatting rules, catching the mechanical issues so the editorial pass can focus on substance.
Fact checking runs during the research enrichment and self-review stages. The system checks every statistic and every link in the article. It reads the cited sources, verifies that quotes are accurate, and confirms that the source actually supports the claim being made. If it cannot verify a stat or find the source, it either finds an alternative source or removes the claim. This directly addresses one of the most common problems with AI-generated content: hallucinated references and fabricated statistics that sound plausible but link to pages that do not contain the claimed data.
Full EEAT scoring happens at the rewrite stage, after a draft exists. The system evaluates the actual article for how well it demonstrates expertise, experience, authoritativeness, and trust signals. If the score is too low, the article does not advance to the next stage until it is strengthened through rewriting.
Autonomous systems are straightforward to build. High-quality autonomous systems that consistently match a skilled human editor with minimal intervention are harder. That gap between “autonomous” and “high-quality autonomous” is where most of the engineering time went.
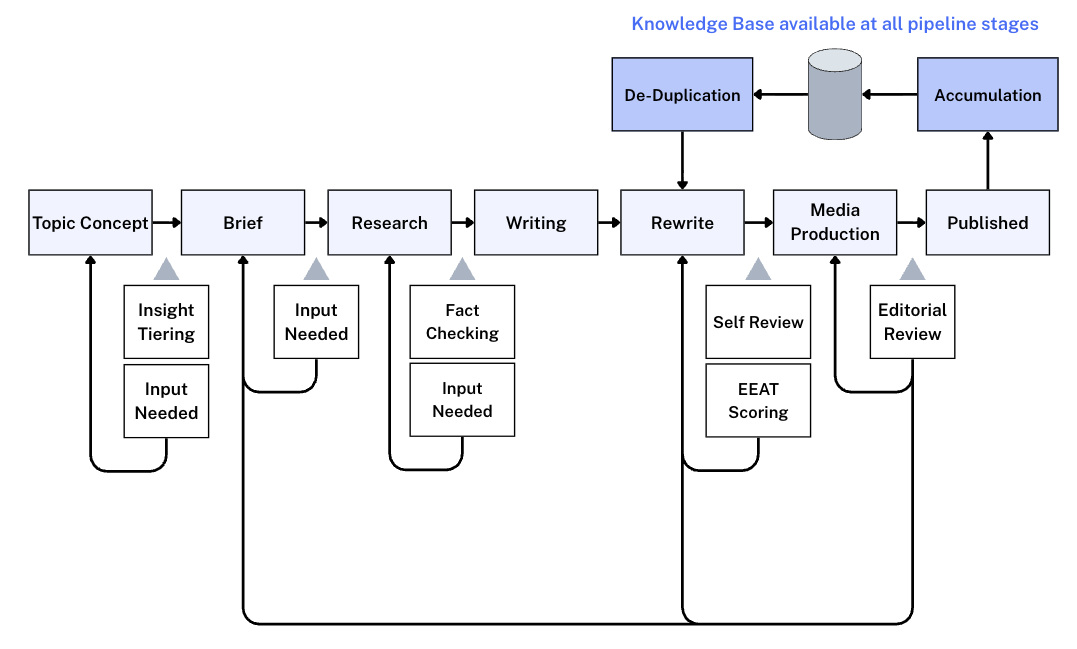
The full content pipeline with quality checks, feedback loops, and knowledge accumulation. Curved arrows show where failed checks cycle content back to earlier stages. The knowledge base feeds into all pipeline stages and accumulates from every published piece.
Human Time Per Article: The Metric That Actually Matters

The number every content leader asks first: how much of my time does this take?
The honest answer is a bell curve, not a single number.
Input time (providing context, reviewing research, interpreting sources like transcripts or meeting notes): 0 to 15 minutes per article, with the bell curve centered at 5 minutes. Some articles need no human input at all because the brief and research are self-contained. Others need 10 to 15 minutes of context that the system cannot find on its own.
Review time (reading the finished draft, checking data accuracy, confirming framing): 0 to 15 minutes per article, bell curve centered at 5 minutes. Most articles need a quick scan and approval. A few need closer reads when the subject matter is nuanced or the data needs verification.
Total human time per article: roughly 10 minutes average, with a range of 1 to 30 minutes.
At $60 per hour, that is about $10 of human time per article on top of the AI costs. This number matters because it is the one most reports omit. Calling something “all-in” while excluding the human review labor is misleading, and careful readers notice.
For comparison: NAV43 reports that structured AI workflows reduce production time from 3.8 hours per article to 9.5 minutes. Those workflows still require a human operator at the center. Our system runs the production stages autonomously. The human shows up for context and review, not production.
What Broke: Failure Modes From 30 Days
Failure data is more useful than success metrics for evaluating system reliability. Anyone can publish throughput numbers.
The early version of the pipeline tried to have one agent handle all stages: research, writing, review, and publishing in one session. That failed comprehensively. The context window filled up, quality degraded with each successive task, and there was no way to diagnose where things went wrong. Splitting into specialized agents with clear handoffs between stages solved it. Each agent does one thing and passes a specific artifact to the next.
The most common pipeline failure is thin research passing to writing. The research agent generates a brief, but sometimes the external data for a topic is genuinely sparse. When the writing agent picks up a brief with insufficient research, the draft comes out shallow or padded with generalizations. We added a quality gate between research and writing to catch this before the writing stage wastes compute on a brief that is not ready. This is a common pattern in why AI pilots fail: upstream data quality determines everything downstream.
The system has a strict no-fabrication rule, but “I found this stat somewhere in my training data and it seems right” is not the same as linking to a primary source. The self-review stage now explicitly checks every stat for an inline source link. If it cannot find one, it flags the stat for removal.
The Subtle Failures
Formatting issues are less critical but persistent: Markdown syntax appearing in HTML content, table markup rendering incorrectly on mobile, image placeholders left in published content because the image generation stage timed out silently. Each of these spawned a specific system fix.
The subtlest failure mode is assumption-based framing, and it is the hardest to automate away. This article is a good example. The first draft led with cost comparisons because the writing agent assumed that is what readers evaluate first. That assumption was wrong. Business owners and agency leaders evaluating autonomous content systems care most about whether the output is good enough to publish under their name, and how much of their time it takes. Cost matters, but it is not the opening argument.
Catching this kind of error requires someone who understands the system’s design philosophy, not just the content. The research was solid. The data was accurate (well, except for the math, which we will get to). The interpretive lens was off. This is the one failure mode that currently requires human intervention to catch, and it happens rarely. Only a couple of articles in four weeks had major framing issues of this type, this article being one of them.
The Honest Rework Picture
The previous draft of this article claimed a 0% rejection rate. That number is technically accurate and contextually misleading.
100% of the articles that reached final human review in the last four weeks were published. Nothing was rejected outright at the final stage. But framing that as “zero rejection” implies the pipeline produces perfect output on the first pass, which is not what happens. Rework occurs throughout the pipeline at different points, and the quality gates are designed to catch problems before they reach a human.
Rework breaks into four categories.
The first is quality gates working as designed. A low insight score holds an article at the idea phase. Insufficient research holds at the research stage. A low EEAT score after the first draft does not advance. These are not failures. They are the quality systems doing their job, blocking weak content early so it never reaches a human reviewer.
Technical issues form the second category: image generation producing wrong media types, chart rendering failures, model capability mismatches like discovering that one model lacks the input tokens for art direction while another handles it fine. These require the system designer to drop in and fix the specific issue.
Teaching vs. Fixing
Every fix gets evaluated for permanence. The question is not “how do I fix this article?” It is “what control knob fixes this class of problem forever?” The pipeline has roughly a dozen control surfaces: memory management, context window allocation, tool access, process sequencing, system design, logical flow controls, and monitoring layers. Each failure mode gets mapped to the control surface that prevents recurrence. The cost trajectory tells the story: API costs deliberately rose from $2-$5 per article to $8.50 as quality systems were added. Each investment closed a specific quality gap.
Framing and assumption errors are the closest thing to “send it back.” Intent gets skewed through multiple pipeline stages, or an assumption about what the reader cares about is wrong. Only a couple of articles in four weeks had major framing issues. The teaching analogy applies: if a student does not get an A, the question is what the teaching system failed to provide.
The system designer’s philosophy throughout all of this: if a problem happens, the response is never just fixing the immediate article. It is identifying the permanent fix. This iterative tightening across dozens of articles is why the final-review rejection rate dropped to zero. Not because the pipeline is perfect, but because the quality gates catch problems before they reach that stage.
Throughput: What the Pipeline Actually Produces
In the most recent four-week period, the pipeline produced:
- 20 new blog posts (original research-backed articles, 2,500 to 4,000 words each)
- 7 new pages (service pages, landing pages, and author pages)
- 9 work orders with edits to existing pages (ranging from targeted link additions to full section rewrites; some work orders bundle multiple small changes like meta description updates)
Total: 36 distinct pieces of content. Not all are equivalent in effort. A 3,500-word blog post with six images runs through the full pipeline. A meta description update on three existing pages takes minutes. Reporting them as a single throughput number would be misleading, so the breakdown matters.
The production constraint is human review bandwidth, not agent speed. An article that clears research and writing in 20 minutes can sit for days waiting for editorial sign-off. The pipeline’s operational bottleneck is producing content faster than a human can review it. When the review queue backs up, the system keeps producing while items wait for approval.
For comparison: Averi.ai’s 2026 benchmarks report recommends 2 to 4 posts per week as the optimal publishing cadence for Seed-to-Series A companies, with companies publishing 16+ posts monthly generating 3.5x more traffic. Our pipeline exceeds that threshold on blog posts alone, with page creation and existing-page optimization running in parallel.

Cost: Accurate Numbers, Honestly Labeled
The first draft of this article had cost numbers that contradicted each other. It claimed $8.50 per article in API costs, $225 per month total infrastructure, and roughly $4.60 “all-in” per article. The math does not work: $8.50 times 36 articles exceeds $225 before infrastructure costs even enter the picture. The “all-in” label was wrong because it excluded human review time.
Here are the corrected numbers from actual invoices.
Writing and review API cost: $8.50 per article average over the last four weeks. This covers all the AI model calls for research enrichment, writing, self-review, editorial review, art direction, and deduplication. The increase from $2 to $5 early on to $8.50 reflects deliberate quality investments: adding the deduplication stage, knowledge capture, and an independent editorial agent.
SEO research API cost: approximately $3.50 per article for the research agent that generates briefs from search console data and competitive analysis.
Server infrastructure: $40 per month for the AWS instance that runs all agents. Additional tool costs (APIs, monitoring, search tools) are variable but do not exceed another $30 per month baseline. Other agents share this server, but the content pipeline is the highest-cost tenant.
Human review time: approximately $10 per article at $60 per hour, based on the ~10 minute average described above.
What these numbers do NOT include: development time. We spend roughly an hour per day building new systems, testing improvements, and optimizing the pipeline. This is building the machine, not running it. If all we were doing is maintaining what we have, a few hours per month would cover updates, issue resolution, and unforeseen situations. Getting to that maintenance-only state requires a stability period where new feature development slows down.
Putting it together for a single article:
| Cost Component | Per Article | Notes |
|---|---|---|
| Writing & review API | $8.50 | 4-week average across all pipeline stages |
| SEO research API | ~$3.50 | Brief generation from search console + competitive data |
| Infrastructure share | ~$1.95 | $70/month fixed costs across ~36 pieces |
| Human review time | ~$10.00 | ~10 min avg at $60/hr (input + review) |
| Total per article | ~$24 | Excludes development/build time |
Roughly $24 per article, including human time but excluding the development investment in building the pipeline itself. That is a more honest number than “$4.60 all-in.”
The comparison to traditional content production is still significant. Averi.ai reports that purpose-built AI content engines cost $8 to $12 per article in platform fees, plus $50 to $100 total when you add human review. Traditional agency rates run $500 to $2,500 per article. Digital Applied’s solo operator model reports effective costs of $5 per piece with AI assistance. Our $24 fully loaded is higher than the API-only numbers that most platforms advertise, and lower than any model that includes honest human time accounting.
The human equivalent for the work this pipeline performs, if you were hiring individual specialists at market rates, runs $15,000 to $25,000 per month for a researcher, writer, editorial reviewer, and social media manager. The pipeline does not replace everything those people do. It replaces the volume-production component of their roles. The human time shifts from producing content to reviewing it and providing context the system cannot find on its own.
GEO Impact: AI Search Citation Performance
Most companies do not track this metric. We do.
GEO (Generative Engine Optimization) measures whether AI search engines cite your content in their responses. We track citation rates across nine AI engines: ChatGPT, Perplexity, Claude, Gemini, Grok, Copilot, Meta AI, Google AI Overview, and Google AI Mode.
Over four weeks of pipeline operation, our overall AI search citation rate improved from 20% to 32% across those nine engines. For specific queries, the results are more targeted. On “how to prioritize AI projects,” we hold position three with 21% share of voice.
Averi.ai reports that AI Overviews now appear on 30% to 48% of Google searches, and 89% of B2B buyers use generative AI during purchasing research. Content that gets cited in those AI responses has an outsized influence on purchase decisions, and most content teams are not tracking it at all.
What seems to drive AI citation in our data: specificity. Articles with exact numbers, named systems, comparison tables, and direct answers to common questions get cited more than articles with general frameworks. Content with statistics sees 28% to 40% higher visibility in AI search, per Averi.ai’s analysis. The pieces that perform best for GEO are the ones where we publish data nobody else has.
Both the 20% starting point and the 32% current measurement are during pipeline operation. We did not have GEO tracking infrastructure before the pipeline launched, so we cannot compare to a pre-pipeline baseline. The improvement is real, but we cannot attribute it solely to the pipeline versus general content accumulation.
The Full Comparison
The benchmarks from the sections above, consolidated against available industry data:
| Metric | FC Pipeline (4 Weeks) | Industry Benchmarks | Source |
|---|---|---|---|
| Human time per article | ~10 min avg (range: 1-30 min) | 3.8 hours (manual); 9.5 min (AI workflow, human-operated) | NAV43 |
| Cost per article (fully loaded) | ~$24 (API + infra + human time) | $50-$100 (AI platform + review); $500-$2,500 (agency) | Averi.ai |
| API cost per article | $8.50 (writing/review) + $3.50 (research) | $8-$12 (purpose-built engines) | Averi.ai |
| Monthly output | 20 posts + 7 pages + 9 edit WOs | 2-4 posts/week (recommended target) | Averi.ai |
| Final-review rejection rate | 0% (quality gates catch issues upstream) | 1 in 5 (manual); 1 in 50 (AI workflow) | NAV43 |
| AI search citation rate | 32% across 9 engines (up from 20%) | Not tracked by most teams | FC proprietary (LLM Refs) |
| Monthly infrastructure | ~$70 (server + tools) | $15K-$25K salary equivalent | Market rate comparison |
The gap between pipeline costs and traditional production costs is dramatic enough that it warrants skepticism. A few things to keep in mind:
The ~$24 per article is a marginal production cost for a system that already exists. It does not include the months of engineering time to build and tune the pipeline.
The 36 pieces per month include blog posts, new pages, and targeted edits to existing pages. Not all are equivalent in effort or API cost.
The salary equivalent comparison ($15K to $25K per month) assumes you need all those roles full-time. The comparison is most meaningful for organizations where content is a primary growth lever and volume justifies dedicated resources.
Could This Work for Your Business?
Three qualifying questions from 30 days of running this system:
Do you publish content regularly? If you publish fewer than 4 articles per month, an autonomous pipeline is probably over-engineered for your needs. AI writing tools with human editing would be simpler and cheaper. The pipeline makes economic sense when volume is high enough that human bottlenecks create real constraints.
Is content a measurable growth lever? If content drives leads, rankings, or AI search citations for your business, the compound effect of higher publishing velocity is significant. If content is a nice-to-have, the pipeline investment will not pay back.
Are you spending $3,000+ per month on content production? That is roughly the break-even point where the infrastructure and setup costs of an autonomous pipeline start to make economic sense compared to hiring or outsourcing. Below that threshold, the complexity is not justified.
If you answered yes to all three, an autonomous pipeline is worth evaluating. If you are not sure whether your organization is ready for this level of automation, our AI readiness assessment is a good starting point.
Frequently Asked Questions
How much human time does an autonomous content pipeline require per article?
In our system, total human time averages roughly 10 minutes per article, split between providing input/context (0 to 15 minutes, bell curve at 5) and reviewing the finished draft (0 to 15 minutes, bell curve at 5). Some articles need zero human input. A few need 30 minutes when the subject matter is nuanced. The key distinction from AI-assisted workflows is that the human reviews output rather than driving production.
What quality controls does the pipeline use?
Six layers: insight tiering at the idea stage screening for EEAT potential, four-tier insight scoring before writing begins, automated fact checking during research and self-review, full EEAT scoring at the rewrite stage, independent editorial review from a separate agent with fresh context, and cross-article deduplication with cumulative knowledge capture. Since adding the independent editorial agent, the final-review rejection rate is 0% across 36 pieces. Quality gates earlier in the pipeline catch problems before they reach human review.
What is the actual cost per article?
Roughly $24 per article fully loaded: $8.50 writing/review API, $3.50 research API, $1.95 infrastructure share, and $10 in human review time at $60/hour. This excludes the development investment in building the pipeline. For comparison, Averi.ai reports $50 to $100 for AI platforms with human review, and $500 to $2,500 for traditional agency work.
What are the common failure modes?
Four categories: (1) quality gates working as designed, holding weak content at early stages; (2) technical issues like image generation failures or model capability mismatches; (3) teaching opportunities where each fix becomes a permanent system improvement; (4) framing errors where the research is solid but the interpretive angle is wrong, which currently requires human judgment to catch. The most useful design principle: every failure should produce a permanent fix, not a one-time correction.
How do you measure AI search citation performance?
We track citation rates across nine AI engines (ChatGPT, Perplexity, Claude, Gemini, Grok, Copilot, Meta AI, Google AI Overview, and Google AI Mode) using LLM Refs monitoring. Our citation rate improved from 20% to 32% over four weeks. Both measurements are during pipeline operation; we lack a pre-pipeline baseline. Most companies do not yet have GEO measurement infrastructure in place. Specificity and first-party data appear to be the strongest citation drivers.
How does an autonomous pipeline compare to a traditional content team?
An autonomous pipeline handles volume production at a fraction of the cost ($70/month infrastructure plus $12 per article in API costs, versus $15,000 to $25,000/month in equivalent salaries). It enforces consistency that humans cannot maintain across 20+ articles per month. It does not replace the human judgment needed for content strategy, editorial direction, and catching framing assumptions. The best results come from combining autonomous production with human oversight, where each intervention improves the system rather than just the individual article.
Is autonomous AI content as good as human-written content?
A Harvard Business School study (Dell’Acqua et al.) found AI users produced work 25.1% faster at 40% higher quality ratings in controlled conditions. In practice, the quality ceiling for a single exceptional piece is higher with a skilled human writer. The quality floor across 20+ pieces per month is higher with an autonomous pipeline. Autonomous content is more consistent, more thoroughly sourced, and more reliably formatted. It is less likely to find an unexpected angle or make a genuinely original argument without strong human input at the briefing stage.
