
AI Meta + Google Ad Monitoring Platform
Unleashed Consulting runs paid advertising for roughly 80 local pet-services businesses across Google Ads, Meta, and Local Services Ads. Their media buyers are good at what they do. The challenge isn’t skill: it’s math. Each client runs on multiple platforms. Each platform has its own dashboard. A buyer doing deep optimization on one account is, by definition, not watching the other seventy-nine at that moment.
They wanted to change the ratio. Instead of deep-diving a handful of accounts per day and sampling the rest, they wanted every client getting expert-level attention on every cycle, and they wanted that coverage to scale as the client book grows, without scaling headcount to match.
We built Pepper Ad Coach to give them just that. The system monitors all connected accounts on a two-hour cycle, scores campaign health against each client’s own targets and baselines, and pushes two kinds of output: alerts when a metric crosses a threshold worth acting on, and coaching — what a strong media buyer would look at next, prioritized by urgency. Critical alerts fire instantly to Slack and email. Everything else batches into a morning digest. A web dashboard rolls up the full portfolio so the team sees where today’s highest-value work is at a glance.
New clients onboard through a self-service portal that connects their ad accounts. No engineering ticket, no setup delay. The agency’s upfront build cost was low, and ongoing costs scale per customer, their investment grows only as the client book grows, not before. That pricing predictability comes from a deliberate architecture choice: Pepper uses AI heavily at build time to author the system’s expert judgment, but makes zero LLM calls at runtime. The intelligence is compiled into lookup tables once, then the production system runs on pure arithmetic. No per-query AI costs, no output variability.
What Pepper actually does
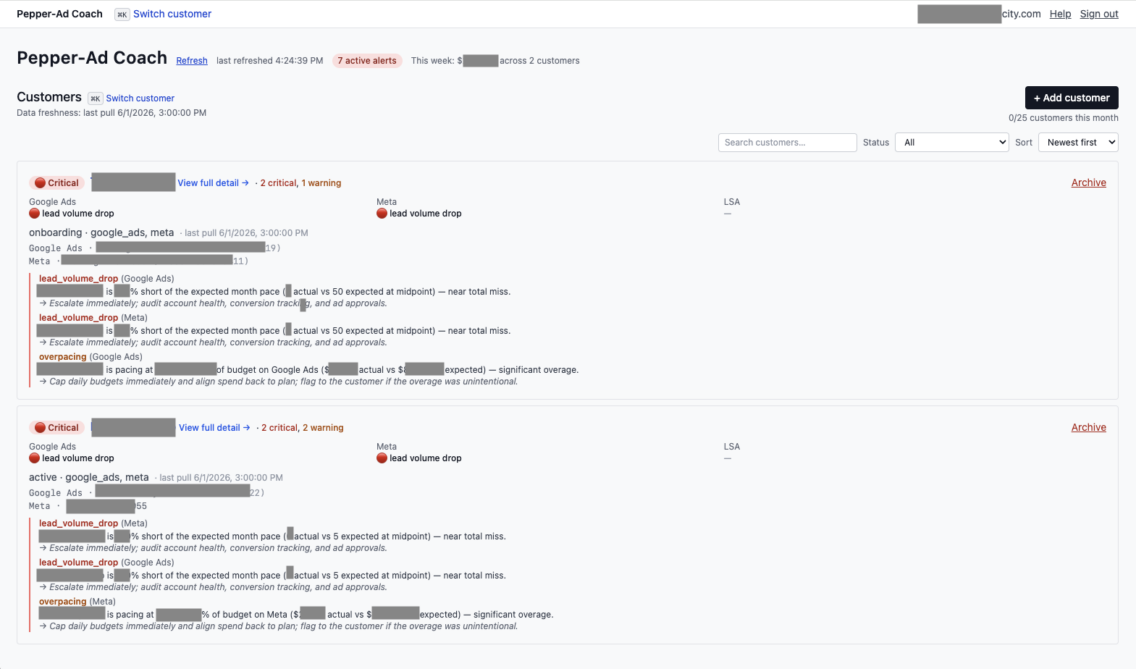
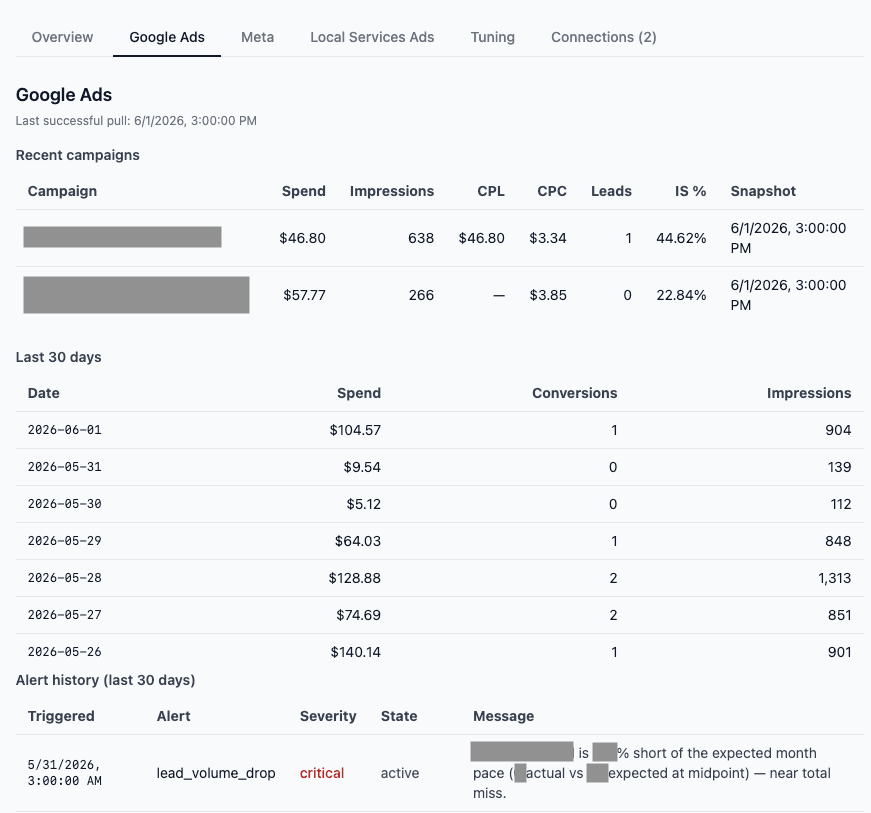
Every two hours during business hours, for every client, on every connected platform, Pepper pulls the latest campaign numbers, evaluates them against that client’s own targets and recent baseline, and produces two kinds of output.
The first is alerts: a campaign crossed a danger threshold. There are seven defined alert types: cost-per-lead spikes, zero-lead-after-spend stretches, budget overpacing, click-through-rate collapse, and so on. Critical alerts go out instantly. Lower-severity warnings batch into a single 8 a.m. daily digest so the team is not drowning in pings.
The second is coaching: nothing has broken yet, but here is what a good media buyer would do next. Coaching items are prioritized as act today, act this week, or act this month.
Delivery sits where the team already works: Slack and email for push notifications, plus a web dashboard with a rolled-up view across all clients (critical rows auto-expand so fires surface to the top). New clients onboard through a self-service portal that connects their ad accounts. No engineering ticket required.
Zero LLM calls at runtime
Most products marketed as “AI-powered” call a large language model every time they do something. At agency scale, that approach hits three chronic problems:
- Cost scales with volume. Multiplying clients by evaluation cycles by campaigns produces a large, variable bill that’s hard to price a flat monthly fee against.
- Outputs are opaque. The model says “lower your bids” and you often cannot fully explain why. It might say something slightly different on the next run with identical data.
- The system is hard to test. The same input can produce different output, which makes regression testing fragile. How often are you okay with it saying the wrong thing?
Pepper inverts the pattern. It uses LLMs heavily, but only once, at build time, to author the system’s judgment. At runtime, the hot path is pure deterministic calculation. The mental model is “compile the expertise once, run it cheaply forever.” It’s the difference between hiring a consultant to write you a decision playbook and paying the consultant every time you have a question.
The pattern has a name in the research literature. A recent paper on compiled AI defines the paradigm as one where LLMs generate executable artifacts during a compilation phase, after which workflows execute deterministically without further model invocation. The trade is runtime flexibility for predictability, auditability, cost efficiency, and reduced security exposure.
Inside the Decision Matrix

The expert judgment lives in a set of lookup tables we call the Decision Matrix. In Release 1 there are 15 matrices containing a total of hundreds of unique cells.
We check the different input properties against 2 to 4 dimensional tables, and find the corresponding alert or recommendation. Each combination of factors is considered once, cached to the table and then returned when the same conditions are met again in the future. Deterministic systems are advantageous because they always produce identical outputs.
For the user of the system, what they see is a template in the format: {customer.name}'s CPL on {platform.name} is {metric.cpl_value} ({metric.cpl_delta_pct}% above 7-day avg) which then renders as something like “Spot Doggie Care on Google Ads is well above the 7-day average.”
A coaching example might be something like:
{Customer} Google Ads quality score is low (6/10) but rank-loss is modest.
The bidding side is okay; the relevance side needs work.
→ Refresh ad copy and landing-page relevance to lift quality score before raising bids.
For the agency owners an approach like this has the payoff that they get a much lower monthly fee because runtime costs do not increase linearly with usage. If we want to change how Pepper reasons, we update the cache tables with a new round of test-data through the LLMs. One-time runs all baked in for maximum cost efficiency.
The honesty discipline: what we dropped
The team was disciplined about not faking sophistication. Where a “smart” signal needed data the system does not have, we either proxied it transparently or dropped the dimension entirely.
Lead quality is the clearest example of a transparent proxy. It needs CRM data Pepper does not have in Release 1, so it is approximated from the cost-per-lead ratio and labeled as an honest simplification. A “search-terms relevance” dimension was dropped because it required LLM judgment at runtime, violating the zero-runtime-LLM principle. An “audience size” dimension was dropped because it required hardcoded vertical guesses that turned out to be a poor signal.
A product that admits what it does not know tends to read as more trustworthy than one that pretends to know everything. Every dropped dimension is a small surface where the system could have been wrong; cutting them raises the average quality of what is left.
Engineering decisions that shaped the system
One OAuth connection per client, not a master connection. Pepper authorizes each client’s ad accounts independently. It costs a bit more onboarding effort and buys fault isolation: if one client’s token expires, only that one client goes dark. For a system whose entire value is aggregate coverage, blast-radius containment is essential.
Idempotent reconnect over clever reconnect. An early production bug taught this. A “Reconnect” button could collide with a stale database record and throw an error, forcing a support cycle. The fix made the operation always-succeeds idempotent. For client-facing surfaces, reliability beats elegance.
Noise control as a design goal. Critical alerts fire instantly; everything else batches into the 8 a.m. digest, with de-duplication so the same problem does not re-alert every two hours unless it materially worsened. A monitoring tool that cries wolf gets muted; restraint is the feature.
Security by elimination, not addition. Rather than bolting on widgets, Pepper removes whole categories of risk. There are zero inbound network ports on the server and database; public traffic reaches the dashboard only through a Cloudflare Tunnel, with no open web port and no SSH to attack. Administrative access goes through AWS Session Manager. Client OAuth tokens are encrypted at rest with managed keys, and the database lives in a private network with no internet access. Pepper is also broadcast-only: it sends and never listens, so there is no inbound-message parser to harden against injection. The harness components that make a setup like this work apply to any production agent system; we cover them in Anatomy of an Agent Harness.
How it was built: 11 business days, AI-driven, human in review
Pepper was built by an agent-driven development pipeline with a human in a review-and-decide role rather than hand-coding every line. An AI coding system drove implementation with cross-model adversarial review (a second model independently critiques the first’s work before it’s accepted), and work was tracked as discrete units the human approved at defined quality gates.
The numbers from the project-coordinator side:
- Pre-build planning ran across a handful of working sessions to lock the spec.
- Spec-done to UAT-ready took about 11 business days.
- The AI worked unsupervised in multi-hour stretches across the build.
- Spec conformity on the second pass through all the requirements was very high, with only a couple of minor issues.
Coding steps were quick to supervise. The longest human-time investment was application authorization with Meta and Google: OAuth app review, scope justification, and platform paperwork. The model-on-model implementation loop has gotten fast enough that the human bottleneck has moved upstream of code, into platform-integration paperwork and scope decisions. A similar pattern shows up in our Voice Intelligence Platform case study, where AI drove implementation while a human directed architecture.
The business payoff
From the agency owner’s side, the system changes four things:
- Proactive instead of reactive. Problems get caught within roughly two hours of starting.
- Whole-portfolio coverage that scales. One team can effectively oversee 80+ clients because the system does the continuous watching and the consistent first-pass diagnosis.
- Consistent quality. Every client gets the same expert-grade first look regardless of which buyer is assigned.
- Defensible advice. Every recommendation traces to an explicit rule and real numbers, which is what you actually need in front of a client.
The deterministic architecture is what lets the pricing be predictable on both the agency side and the reseller side. Cost per end-customer scales with the size of the client book, and the math works for all three parties: the end client gets proactive monitoring that did not exist before, the agency gets a margin on a product they can stand behind, and we get a predictable recurring revenue line on infrastructure that does not get more expensive when usage goes up. Read more in our Agency & Reseller Solutions.

The build-vs-buy trade is covered in Build, Don’t Buy AI Agents, and the agency economics in White-Label AI Agents for Agencies. Custom systems make sense when off-the-shelf SaaS covers the wrong 80% of the workflow. Ad monitoring at agency scale, with this aggregate view and pricing predictability, turned out to be one of those cases.
Frequently Asked Questions
What does “zero AI calls at runtime” actually mean?
It means that when Pepper does its work (pulling campaign data, evaluating it, producing alerts and coaching), it does not call a large language model at any point. The expert judgment was authored ahead of time, with LLM assistance, into lookup tables. The runtime sorts live numbers into buckets, looks up the matching cell, and renders a template. No model invocation, no token cost per request, no variability from one run to the next.
How is this different from tools like Optmyzr or Revealbot?
The category overlaps, but in our experience the core function differs. Optmyzr and Revealbot are PPC management platforms; they help you change bids, build campaigns, manage budgets, and report on activity. Pepper is a monitoring and coaching layer that sits above whatever campaign management you are already doing. It does not run your campaigns; it watches them on a two-hour cycle across the whole client book and tells you where to focus. There is an architectural split too: most modern “AI-powered” ad tools call an LLM on every analysis, with the cost and variability that brings. Pepper is built the opposite way, with the AI work done once at build time and the production system deterministic.
Could this “compile the expertise” pattern work outside advertising?
Yes, in domains where the judgment can be reasonably captured as a finite set of conditions and recommended actions. Compliance monitoring, support triage, policy routing, and quality assurance for repeatable processes are all candidates. The honest constraint: the more open-ended and context-dependent the judgment, the worse the lookup-table approach fits. The pattern works where a human expert could write a decision playbook; it does not work where every situation is genuinely novel and needs fresh reasoning. Ad metrics relative to a baseline are a bounded reasoning problem, which is why this architecture is the right call for it.
